A web address (URL) has four parts to it, as follows:
http://www.companyname.co.za/path1/subpath1/file.htm
- The first part of this address (http://) stands for ‘Hypertext Transfer Protocol’, and indicates that the this address is a Web address – it could have been an FTP address, for example.
The next part of the address (www.companyname.co.za) refers to the host name of the computer on which the web page is located. The ‘www’ is a common part of the address but is not a specific requirement – some web addresses do not have the ‘www’ as part of the address. The co.za, in turn, refers to the domain in which the computer is located. This domain could be a country specific domain such as in the above example (the example refers to a South African company domain – co.za), or a general domain such as .com which is a very common global (also called ‘top-level’) domain.
The middle part (/path1/subpath1/) is nothing more than the directory path on the host computer leading to the actual file depicting the web page. There might be no path at all, or the path could be quite long.
2. Finally, at the end of the path you will find a file name (file.htm) which refers to the file containing the web page concerned. If there is no file name, it doesn’t mean there is no Web page; it simply means that the file name is an assumed default file name such as index.htm, welcome.htm, home.htm, or something similar.
The fact that every web page has its own unique web address (URL), means that web page designers can associate (or link) the URL of any relevant web page with any element (such as a graphic, picture or piece of text) on a web page they are designing and when you as user click on that particular element, you will be taken (or linked) automatically to the web page the URL refers or points to. Very simple!
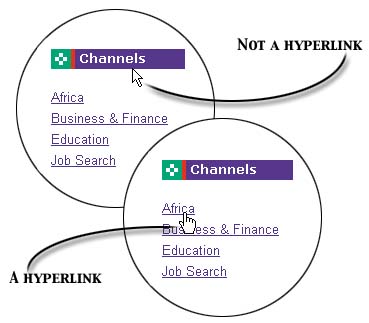
How do you know that a particular element is a hyperlink? Well, when you move your mouse cursor over an element that is a hyperlink, the arrow cursor changes to a pointing hand!