Search engines usually have three parts to them.
- Software that crawls the Web, jumping from web page to web page looking for new web pages or web pages that have recently been updated. These software programs are called ‘crawlers’, ‘spiders’ or ‘robots’ (or sometimes just ‘bots’)
-
Once a new web page has been found, the next part of the search engine kicks into place. This is the ‘harvesting’ part of the search engine software. What this software does is to catalogue and index all of the information contained on the web page into the search engine’s own database. The search engine thus builds up its own database of the information contained on web pages.
-
The third part of the search engine is the actual search software that attempts to match the keywords that you have entered into the search query box with the indexed information contained in the search engine’s database.
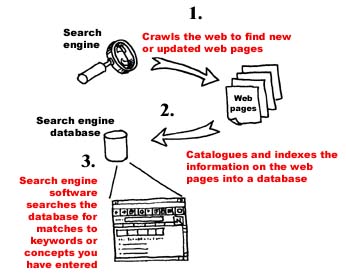
When you enter your query, the search engine does not immediately go onto the Internet to find the web pages that contain the words that match
A search engine such as Google maintains an index in excess of 8 billion web pages, while Alta Vista has a database of over 1 million pages. Others such as Excite and Lycos have smaller databases of around 500-800 million pages.
